Jak dodać voiceover do wideo: Kompletny przewodnik (2026)
Dowiedz się, jak dodać voiceover do wideo za pomocą AI, profesjonalnego mikrofonu lub swojego telefonu. Nasz przewodnik obejmuje nagrywanie, synchronizację, edycję i optymalizację audio dla mediów społecznościowych.
Pewnie już to robiłeś. Wizualizacje są czyste, cięcia ostre, napisy wyglądają dobrze, a wideo nadal wydaje się płaskie, gdy tylko je odtworzysz. Zwykle problem nie leży w materiałach filmowych. To voiceover.
Na platformach z krótkimi formami widzowie wybaczą wiele, zanim wybaczą słaby dźwięk. Stłumiony odczyt, ostry pogłos pomieszczenia, zły rytm lub robotyczny głos AI mogą sprawić, że dopracowany montaż wyda się tani. Czytelny, celowy voiceover działa odwrotnie. Nadaje wideo strukturę, ton i dynamikę.
Dobra wiadomość jest taka, że nauka jak dodać voiceover do wideo nie wymaga pełnego studia. Ważniejsze jest wybranie właściwej metody nagrywania, czysta synchronizacja i praca posprodukcyjna, którą większość tutoriali pomija.
Dlaczego twoje wideo potrzebuje świetnego voiceoveru
Wielu twórców traktuje voiceover jak ostatnią pozycję do odhaczenia. Nagraj coś szybko, wrzuć na oś czasu, obniż muzykę, eksportuj. Ten workflow to właśnie powód, dla którego tyle wideo wygląda lepiej, niż brzmi.
Silny voiceover rozwiązuje trzy powszechne problemy naraz. Wyjaśnia, co widz ogląda, ustala emocjonalny ton i nadaje tempo, gdy same wizualizacje nie wystarczają. To ma znaczenie w tutorialach, prezentacjach produktów, reklamach, treściach bez twarzy, wyjaśnieniach talking-head i prawie każdym formacie krótkim, gdzie pierwsze sekundy decydują, czy ktoś zostaje, czy scrolluje.

Biznesowa strona opowiada tę samą historię. Globalny rynek voice-over był wart 4,2 miliarda dolarów w 2024 roku i ma osiągnąć 8,6 miliarda dolarów do 2034 roku, według danych rynkowych branży voice-over. Taki wzrost odzwierciedla, jak ważna stała się treści z narracją w marketingu, edukacji, reklamach i wideo społecznościowym.
Co naprawdę robi zły voiceover
Zły voiceover nie tylko brzmi niechlujnie. Tworzy tarcie.
- Spowalnia zrozumienie, gdy odczyt jest niejasny lub zbyt szybki.
- Osłabia zaufanie, gdy pogłos pomieszczenia, przesterowanie lub robotyczne sformułowania sprawiają, że dźwięk wydaje się niskiej jakości.
- Szkodzi retencji, bo widzowie muszą się bardziej starać, by śledzić przekaz.
- Niszczy poczucie marki, gdy każde wideo brzmi inaczej.
Dobry voiceover powinien być niewidoczny. Widz nie powinien myśleć o dźwięku. Powinien po prostu dalej oglądać.
Masz więcej niż jedną ścieżkę
Nie ma jednego poprawnego workflow. Są trzy praktyczne.
Niektórzy twórcy używają telefonu, gdy liczy się prędkość bardziej niż poler. Inni nagrywają z dedykowanym mikrofonem, bo ich własny głos jest częścią marki. Jeszcze inni używają AI, bo potrzebują spójności, szybszych iteracji lub wielojęzykowego wyjścia. Wszystkie trzy mogą działać. Różnica tkwi w tym, czy oczyścisz dźwięk i dopasujesz metodę do zadania.
Wybór metody nagrywania voiceoveru
Zła metoda tworzy dodatkową pracę, zanim w ogóle zaczniesz edytować. Widziałem twórców spędzających więcej czasu na naprawianiu pośpiesznego nagrania, niż byliby potrzebowali na zrobienie lepszego od początku.
Wybieraj na podstawie roli voiceoveru w treści. Jeśli twoja publiczność śledzi cię ze względu na osobowość, twój własny nagrany głos ma większe znaczenie. Jeśli prowadzisz maszynę do treści dla reklam, wyjaśnień lub wideo produktowych, skalowalność i spójność mogą być ważniejsze niż wykonanie wokalne.
Porównanie metod voiceoveru
| Metoda | Koszt | Jakość dźwięku | Prędkość i wygoda | Najlepsze dla |
|---|---|---|---|---|
| Smartfon | Niski | Akceptowalna w cichym pomieszczeniu, ograniczona kontrola | Najszybsza do rejestracji | Historie, szybkie aktualizacje, szkice |
| Profesjonalny mikrofon | Średni do wysoki | Najlepsza kontrola i najbardziej naturalny rezultat | Wolniejsza, bo nagrywanie i czyszczenie zabierają czas | Osobiste marki, YouTube, premium reklamy, edukacja |
| Generator głosu AI | Zależny od narzędzia | Może brzmieć mocno przy właściwych ustawieniach, słabiej, jeśli generyczny | Bardzo szybka produkcja i rewizje | Kanały bez twarzy, agencje, treści wielojęzyczne, testy wersji |
Nagrywanie smartfonem działa, gdy liczy się tylko prędkość
Telefon wystarczy do tymczasowych treści, casualowych klipów lub momentów, gdy autentyczność jest ważniejsza niż poler. Jeśli robisz szybką reakcję, aktualizację zza kulis lub post o trendzie tego samego dnia, wygoda może wygrać.
Ale telefony obnażają każdy problem nieleczonego pomieszczenia. Twarde ściany tworzą odbicia. Odległość zabija obecność. Wbudowane mikrofony nie dają dużo miejsca na kształtowanie dźwięku później.
Używaj telefonu, jeśli:
- Musisz opublikować szybko
- Nagrywasz w cichym, miękkim pomieszczeniu
- Treść jest celowo casualowa
Pomiń go, jeśli voiceover niesie tekst sprzedażowy, nauczanie lub pozycjonowanie marki.
Dedykowany mikrofon daje kontrolę
Jeśli twój głos jest częścią produktu, profesjonalny setup mikrofonu jest wart wysiłku. Otrzymujesz lepszy ton, mniej szumów pomieszczenia i dużo bardziej przewidywalne rezultaty w edycji. To najlepsza droga dla twórców budujących rozpoznawalny głos i dla każdego, kto chce, by dźwięk trzymał poziom na YouTube, Instagramie, TikToku i płatnych socialach.
Kosztem jest czas. Ręczne nagrywanie wymaga setupu, powtórek, edycji i podstawowego przetwarzania audio. Ta praca się opłaca, gdy liczy się spójność.
Zasada pracy: Jeśli chcesz, by ten sam głos stał się znajomy w treściach przez miesiące, użyj prawdziwego mikrofonu i zbuduj powtarzalny setup nagrywania.
Generatory głosu AI wygrywają prędkością i skalą
AI to praktyczny wybór, gdy potrzebujesz objętości. Jest też przydatne, gdy chcesz przetestować kilka haczyków, zmienić style narratora, zlokalizować skrypt lub zachować spójny dźwięk w zespole.
Wada jest oczywista. Generyczny output brzmi generycznie. Jeśli nie dostosujesz tempa, akcentów i sformułowań skryptu, rezultat może wydawać się bez życia. AI działa najlepiej, gdy traktujesz je jak narratora, który nadal potrzebuje wskazówek.
Prosty filtr decyzyjny pomaga:
- Użyj telefonu do szybkich, jednorazowych lub bardzo casualowych treści.
- Użyj pro mikrofonu, gdy jakość głosu jest częścią twojej reputacji.
- Użyj AI, gdy najważniejsze są czas realizacji, spójność lub produkcja wielojęzyczna.
Jak nagrywać profesjonalny voiceover ręcznie
Jeśli nagrywasz swój własny głos, większość jakości pochodzi z setupu, zanim w ogóle naciśniesz nagraj. Średni odczyt w kontrolowanym pomieszczeniu zwykle bije świetny odczyt w złym pokoju.

Profesjonalna praktyka jest prosta. Użyj dynamicznego mikrofonu, potem zastosuj filtr górnoprzepustowy na 80-100 Hz i kompresję w proporcji 4:1, by utrzymać głos na stałym poziomie -12 do -6 dB LUFS, jak opisano w najlepszych praktykach voiceoveru w Lightworks.
Zacznij od pomieszczenia, nie od mikrofonu
Świetny mikrofon w odbijającym pomieszczeniu nadal brzmi źle. Zanim pomyślisz o pluginach czy presetach, zmniejsz problemy pomieszczenia.
Dobre prowizoryczne opcje:
- Szafa z ubraniami, bo miękkie materiały pochłaniają odbicia
- Kąt z zasłonami, dywanami i miękkimi meblami
- Setup biurka z kocami lub panelami akustycznymi w pobliżu
Unikaj kuchni, pustych biur i pomieszczeń z gołymi ścianami. Te przestrzenie wyolbrzymiają ostre odbicia i sprawiają, że głos wydaje się odległy.
Technika mikrofonu ma większe znaczenie, niż myślą początkujący
Odległość i kąt kształtują nagranie od razu. Trzymaj się w odległości 15-30 cm od mikrofonu i mów lekko z boku, zamiast prosto w niego. To pomaga zredukować plosives i podmuchy z ust na słowach z twardymi spółgłoskami.
Kilka nawyków poprawia rezultaty szybko:
- Użyj pop filtra: Łapie wybuchy powietrza, zanim trafią w kapsułę.
- Trzymaj otwartą postawę: Zwinięta postawa sprawia, że odczyty brzmią słabo.
- Oznacz swoją pozycję: Jeśli się ruszasz, ton zmienia się między ujęciami.
- Nagraj ton pomieszczenia: Kilka sekund ciszy pomaga przy późniejszym czyszczeniu.
Nagraj krótki test, potem posłuchaj na słuchawkach przed pełnym ujęciem. Naprawianie hałaśliwego setupu po dziesięciu minutach narracji to bolesna lekcja.
Nagrywaj tak, jakby edytor miał dotknąć pliku później
Nie próbuj zaliczyć całego skryptu w jednym heroicznym ujęciu. Nagrywaj w sekcjach. Zostaw pauzę między liniami. Jeśli popełnisz błąd, zatrzymaj się, powtórz zdanie czysto i kontynuuj. To daje oczywiste punkty edycyjne.
Prosty workflow:
- Pisz do mówienia, nie do czytania. Krótsze linie brzmią naturalniej.
- Rozgrzej głos. Zimne pierwsze ujęcie zwykle brzmi sztywno.
- Ustaw gain ostrożnie. Przester psuje dobre ujęcia.
- Nagrywaj w WAV, jeśli możliwe. Daje więcej elastyczności później.
- Zrób dwie wersje kluczowych linii. Jedną neutralną, jedną z większą energią.
Pierwsze czyszczenie
Po nagraniu zrób podstawowe przetwarzanie, zanim zsynchronizujesz z wideo.
- Zastosuj filtr górnoprzepustowy na 80-100 Hz
- Dodaj lekkie EQ dla klarowności
- Użyj kompresji 4:1
- Normalizuj głos do docelowego zakresu
- Usuń oczywiste kliki, oddechy lub zakłócenia tła
To różnica między surowym nagraniem a voiceoverem, który dobrze siedzi w miksie wideo społecznościowego.
Jak generować idealne voiceovery AI z ShortGenius
Skończysz edycję krótkiej formy, wrzucisz głos AI, a rezultat nadal wydaje się tani. Słowa są właściwe. Tempo złe. Ton nie łapie haczyka. Na TikToku i Instagramie ta luka pokazuje się szybko w retencji.
Voiceover AI działa najlepiej jako system produkcyjny, nie magiczny przycisk. Daje szybkie rewizje, spójne wykonanie w partiach i dużo mniej ponagrywań, gdy skrypt się zmienia. Kosztem jest kierunek. Jeśli nie ukształtujesz skryptu, tempa i post-processingu, output brzmi płasko nawet z dobrym modelem głosu.
Niektóre analizy workflowów AI voice raportują duże oszczędności czasu dzięki automatycznemu czyszczeniu i silniejszą reakcję słuchaczy na dobrze wyszkolone klonowane głosy niż na generyczny text-to-speech. To zgadza się z tym, co widzą twórcy w praktyce. Główny zysk to nie tylko prędkość. To możliwość testowania wielu haczyków, tonów i odczytów linii przed finalnym cięciem.
Pisz pod delivery AI
AI interpretuje tekst dosłownie. Gęste zdania, nagromadzone klauzule i niejasne punkty akcentu produkują znajomy syntetyczny rytm, który zabija czas oglądania.
Skrypty budowane pod AI zwykle mają:
- jedną ideę na zdanie
- wyraźne słowa akcentowane blisko końca linii
- krótkie przejścia między scenami
- celowe punkty pauz
- sformułowania brzmiące jak mowa, nie jak publikacja
Skracam też linie otwierające mocniej dla social niż dla YouTube. Jeśli pierwsze zdanie nie trafi czysto w mniej niż trzy sekundy, przepisuję je, zanim dotknę ustawień głosu.
Jeśli potrzebujesz wersji wielojęzycznych, popraw skrypt przed generacją, nie po. Bezpośrednie tłumaczenie często zachowuje znaczenie, ale traci kadencję. Dla zespołów lokalizujących reklamy, tutoriale lub klipy w stylu twórcy, ten przewodnik o tym, jak tłumaczyć pliki głosowe i audio dokładnie, jest przydatny, bo sformułowania i delivery zwykle potrzebują adaptacji przed finalnym renderem.
Workflow w ShortGenius
Dobry workflow AI trzyma pisanie, wybór głosu i rewizje blisko siebie. Dlatego wielu twórców używa ShortGenius do voiceoveru AI i produkcji wideo krótkiej formy zamiast rozdzielać pracę na oddzielne narzędzia do skryptów, TTS, napisów i edycji.
Praktyczny workflow wygląda tak:
-
Szkic po scenach Pisz narrację pasującą do wizualnych beatów, nie do pełnego konceptu.
-
Wybierz głos pasujący do formatu Promosy w stylu UGC potrzebują innego odczytu niż bezosobowe wyjaśnienia czy dema produktów.
-
Ustaw tempo celowo Lekko wolniejsze często brzmi pewniej. Lekko szybsze może działać dla pilności, ale tylko przy rzadkim skrypcie.
-
Wygeneruj krótki sample najpierw Przetestuj haczyk i jedną sekcję środkową przed pełnym skryptem.
-
Napraw złe linie na poziomie skryptu Jeśli akcent brzmi źle, przepisz zdanie. Ustawienia mogą zrobić tylko tyle.
-
Wygeneruj alternatywy Stwórz dwie lub trzy wersje linii otwierającej. To jeden z najłatwiejszych sposobów na poprawę retencji bez przebudowy całego montażu.
Oto walkthrough, jeśli chcesz zobaczyć flow w akcji.
Co odróżnia użyteczne AI od wypolerowanego AI
Słabe voiceovery AI zawodzą w przewidywalny sposób. Skrypt jest przeładowany. Domyślne tempo nietknięte. Głos nie pasuje do footage. Render idzie prosto na oś czasu bez wykończenia audio.
Twórcy osiągający mocne rezultaty na social robią więcej niż generują i eksportują. Traktują narrację AI jak surowy materiał. To znaczy dostosowywanie wymowy, dzielenie długich linii na czystsze frazy i lekką pracę post, by głos przecinał głośniki telefonu bez ostrości.
Narracja AI brzmi naturalnie, gdy skrypt jest dobrze skierowany, a wyeksportowany plik wykończony jak prawdziwy voiceover.
Ten dodatkowy poler sprawia, że AI jest użyteczne do masowej produkcji social. Zamyka też lukę jakościową między szybką syntetyczną narracją a ciasnym, bardziej celowym dźwiękiem kojarzonym z profesjonalną pracą głosową.
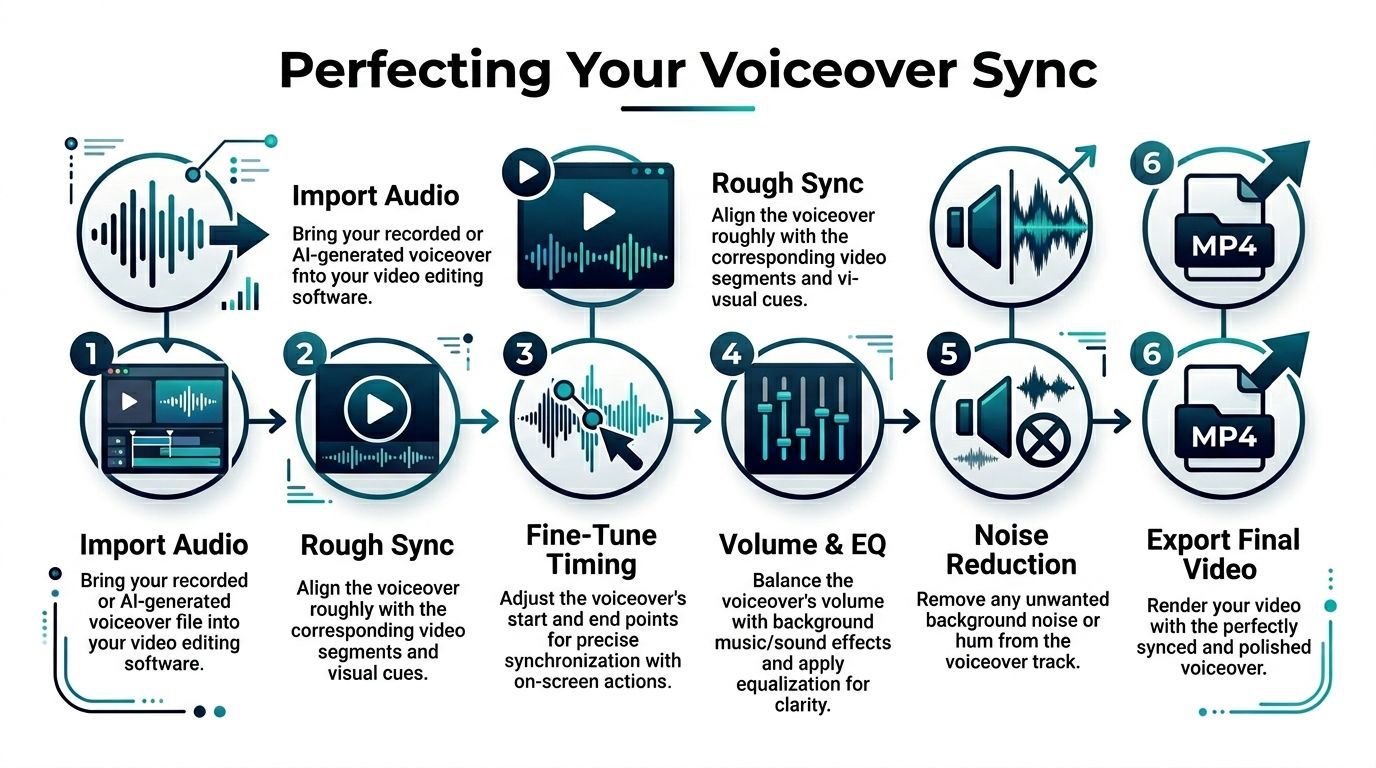
Synchronizacja i edycja voiceoveru do perfekcji
Gdy plik istnieje, trudna część to nie wrzucenie go na oś czasu. To sprawienie, by brzmiał jak native do wideo, a nie nałożony na wierzch.
Jeśli twój klip źródłowy ma już irytujące audio kamery, szum wentylatorów lub przypadkową mowę, wyczyść to najpierw. Proste narzędzie do usunięcia istniejącego audio z wideo oszczędza czas przed synchronizacją finalnej narracji.
Zacznij od rough sync
Zaimportuj audio do Premiere Pro, DaVinci Resolve, CapCut, Final Cut, VEED lub dowolnego edytora, którego używasz. Wrzuć voiceover na oddzielną ścieżkę pod wideo i wyrównaj po znaczeniu najpierw, nie po perfekcji klatki.
Do rough sync skup się na:
- gdzie pierwsza wypowiedziana fraza powinna zacząć
- gdzie akcje wizualne potrzebują wsparcia werbalnego
- gdzie ciszę zostawić w spokoju
Jeśli voiceover był nagrany do skryptu pasującego do edycji, ta część idzie szybko. Jeśli skrypt zmienił się po cięciu, spodziewaj się przycinania linii lub przesuwania klipów.
Dopracuj z waveformami i wskazówkami wizualnymi
Przybliż oś czasu i słuchaj zdanie po zdaniu. Ciasna synchronizacja ma największe znaczenie, gdy narracja odnosi się do widocznej akcji, tekstu na ekranie, ruchu ręki lub revealu produktu.
Używaj:
- szczytów waveform do oczywistych początków mowy
- markerów do kluczowych beatów wizualnych
- małych przycięć zamiast dużych przesunięć, gdy jesteś blisko
Używaj overlap edits do wygładzenia flow
Początkujący cut często brzmi gwałtownie, bo każda linia głosu zaczyna się dokładnie, gdy pojawia się nowy shot. To nie zawsze najlepszy ruch.
Dwa proste wzorce edycyjne pomagają:
- J-cut: Następna linia głosu zaczyna się przed zmianą wizualną.
- L-cut: Bieżąca linia głosu kontynuuje po zmianie wizualnej.
Te edity sprawiają, że wideo wydaje się bardziej celowe i pozwalają głosowi prowadzić widza przez przejścia.
Jeśli cut wydaje się skokowy, nie zawsze naprawiaj obraz najpierw. Często gładniejsza naprawa to przesunięcie audio o ułamek.
Balansuj głos, muzykę i efekty
Po zablokowaniu timingu miksuj ścieżkę. Głos zawsze powinien wygrywać. Muzyka tła powinna wspierać energię bez konkurowania o uwagę.
Praktyczny finishing pass:
- obniż muzykę pod dialogiem
- usuwaj irytujące oddechy tylko, gdy przyciągają uwagę
- fade'uj początki i końce linii czysto
- sprawdzaj przejścia na głośnikach i słuchawkach
- obejrzyj raz bez dotykania osi czasu
Ten finalny watch w czasie rzeczywistym łapie więcej problemów niż nieskończone mikro-dostosowania.
Zaawansowane wskazówki do polerowania audio voiceoveru
Surowy voiceover prawie nigdy nie jest wykończonym voiceoverem. To krok, który większość twórców spieszy, a który często oddziela treści wiarygodne od tych domowych.
Powód jest prosty. Widzowie reagują na dźwięk szybciej, niż świadomie go analizują. Jeśli głos jest błotnisty, hałaśliwy, cienki, ostry lub niespójny, czują opór, zanim zrozumieją dlaczego.
Silnym powodem, by nie pomijać poleru, jest zachowanie publiczności. Badanie Wistia wykazało, że problemy z jakością audio powodują, iż 42% widzów porzuca krótkie wideo w pierwszych 5 sekundach, a badania nad efektem liczneści głosów wykazały, że używanie wielu głosów może zwiększyć perswazyjność i finansowanie na Kickstarterze o ponad 30%, jak podsumowano w opisie SMU o voiceoverach w video marketingu.
Wyczyść szumy przed wzmocnieniem głosu
Wielu ludzi skacze od razu do EQ. To błędne, jeśli ścieżka ma szum, brum, ton pomieszczenia lub niskie pomruki.
Zacznij od usuwania tego, czego nie powinno być:
- Użyj redukcji szumów lekko, by głos nie stał się wodnisty
- Gate ostrożnie, jeśli szum pomieszczenia siedzi między frazami
- Wytnij pomruki, zanim wzmocnisz klarowność
- Przytnij złe oddechy i kliki ust tylko, gdy irytują
Ciężkie czyszczenie może sprawić, że głos brzmi gorzej niż oryginał. Celem nie jest sterylny dźwięk. To kontrolowany dźwięk.
EQ dla klarowności, nie dla efektowności
Dobre EQ zwykle brzmi nudno w trybie solo i świetnie w pełnym miksie. Starasz się stworzyć zrozumiałość, nie dramę radiową.
Przydatne ruchy:
- Filtrowanie górnoprzepustowe, by oczyścić niskie pomruki
- Wycinanie błotnistych niskich średnich, jeśli głos wydaje się zamknięty
- Dodanie lekkiej prezencji, by spółgłoski brzmiały wyraźnie
- Redukcja ostrości lub sybilancji, jeśli górny koniec gryzie
Jeśli usłyszysz dramatyczną transformację po jednym agresywnym ruchu EQ, to często za dużo.
Kompresja to narzędzie spójności
Kompresja utrzymuje głos na wierzchu dla widza zamiast skakania po głośności. Pomaga cichym liniom pozostać zrozumiałymi i trzyma głośniejsze od wyskakiwania.
Co działa:
- umiarkowana kompresja
- redukcja gain brzmiąca kontrolowanie, nie zgnieciona
- dopasowanie poziomu wyjściowego po kompresji
Co nie działa:
- miażdżenie życia z odczytu
- nadmierne rozjaśnienie po kompresji
- próba naprawy złej techniki mikrofonu pluginami
Praktyczna zasada: Jeśli słyszysz pracę kompresora, cofnij go.
Tempo, cisza i wiele głosów
Poler audio to nie tylko technika. To edycja.
Czasem najinteligentniejszy ruch to zostawienie pół sekundy ciszy przed lądowaniem kluczowej linii. Czasem to wycięcie frazy powtarzającej to, co pokazuje wizual. A w niektórych formatach dodanie drugiego głosu tworzy kontrast trzymający uwagę.
Wiele głosów jest szczególnie przydatne do:
- reklam w stylu dialogu
- skeczy i promos UGC
- porównań przed-po
- tutoriali z liniami gospodarza i klienta
Ważne jest umiar. Dwa różne głosy mogą brzmieć dynamicznie. Za dużo głosów sprawia, że krótkie wideo wydaje się bałaganem.
Eksport i publikacja wideo na social media
W momencie eksportu decyzje kreatywne powinny być już skończone. Eksport to ochrona pracy, nie nadzieja, że platforma to naprawi.
Trzymaj finalny plik prosty i przyjazny platformom. Eksportuj z czystym audio, potem obejrzyj render przed wrzuceniem gdziekolwiek. Problemy często pokazują się dopiero po eksporcie, zwłaszcza gwałtowne cięcia, brak fade'ów i muzyka głośniejsza niż oczekiwano.
Finalna checklist przed publikacją
- Obejrzyj pełny eksport raz: Nie scrubuj. Odtwórz do końca.
- Sprawdź pierwsze sekundy dokładnie: Linia otwierająca musi być klarowna od razu.
- Zweryfikuj napisy: Napisy powinny wspierać voiceover, nie walczyć z nim.
- Posłuchaj na głośnikach telefonu: Tam dużo treści krótkich jest ocenianych.
- Sprawdź balans muzyki jeszcze raz: Miks dobry na słuchawkach może zmętnieć na mobile.
- Upewnij się, że zakończenie rozwiązuje się czysto: Bez obciętego ostatniego słowa, ogona muzyki czy niezręcznej ciszy.
Napisy są częścią strategii audio
Dobry voiceover i dobre napisy pracują razem. Napisy pomagają widzom bez dźwięku, poprawiają dostępność i wzmacniają kluczowe linie, gdy otoczenie feedu jest hałaśliwe lub rozpraszające.
Dla TikToka, Instagram Reels, YouTube Shorts i Facebook video najlepsze rezultaty to zwykle klarowny ścieżka mówiona z czystym tekstem na ekranie. Jeśli głos wyjaśnia, a napisy czysto powtarzają przekaz, wideo staje się łatwiejsze do śledzenia w więcej warunkach oglądania.
Publikacja mocnego wideo z narracją sprowadza się do jednego nawyku. Nie traktuj audio jak warstwy. Traktuj je jak kręgosłup wideo.
Jeśli chcesz szybszy sposób na skrypty, generowanie naturalnych voiceoverów, składanie scen, dodawanie napisów, zamianę wariantów i publikację na kanałach z jednego workflow, wypróbuj ShortGenius (AI Video / AI Ad Generator). Zbudowany dla twórców i zespołów, którzy chcą zamienić pomysły w wypolerowane wideo social bez szycia stosu oddzielnych narzędzi.